
Machine translation: faster, more, better?


The concept of machine translation (MT) was conceived in 1947 by Warren Weaver, an American cryptographer who, in a letter to Norbert Wiener, called the father of cybernetics, first mentioned the possibility of using the newly developed computers to translate texts. 70 years later, great achievements have been made in this field.
Translation quality has greatly improved due to the recent emergence of neural machine translation (NMT) based on deep learning technology. The Translated company, operating in the translation industry, has published a report stating that the quality of machine translations is quickly approaching that of those done by humans. Within the next six years it is said to match the quality of the output produced by highly-skilled translators.
The effectiveness indicator
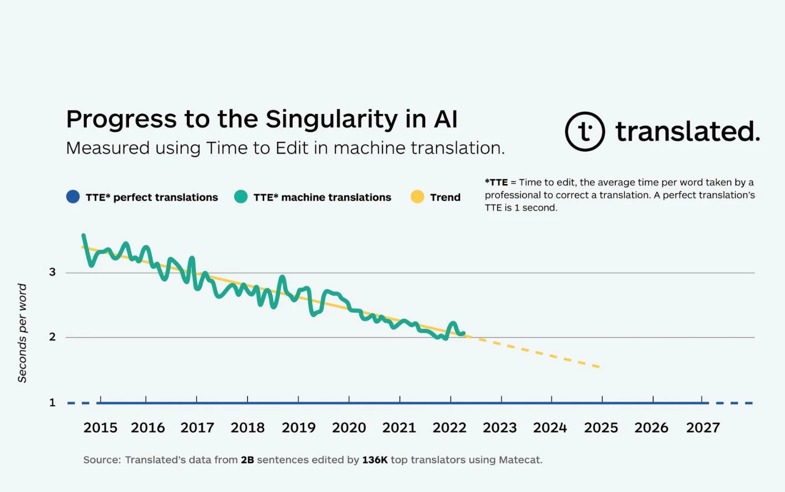
For years, the Translated experts have been refining tools for evaluating and monitoring the quality of machine translation. In 2011, they finally standardized their methodology and established a metric they called “Time to Edit” (TTE) which is calculated as the total time it takes the world’s best professional translators to proofread and correct the translation of a segment suggested by MT, divided by the number of words making up that segment. “We believe that TTE is the best measure of translation quality,” the report reads. Compared to other MT quality evaluation methods, TTE provides a better assessment of the translator’s cognitive effort needed during post-editing of the translated content.
The company’s specialists have been keeping track of the average TTE for years. Machine translation researchers had never before had the opportunity to work with such large amounts of data collected under working conditions, which included records of the time it took to edit more than 2 billion MT segments by tens of thousands of professional translators worldwide. The translations covered a wide range of subject areas, from literature to technical translations, as well as those that MT still struggles with, such as speech transcription. The conclusion? The amount of time spent on post-editing machine translations is steadily decreasing.
Nearing perfection
According to the report, a “perfect” translation (i.e., one that does not require any post-editing) should have a TTE of one second, taking into account the time it takes the translator to read and process the text. In 2017, the average TTE for MT was around three seconds, but this figure has been steadily declining and now amounts to just over two seconds (a drop of slightly more than one-tenth of a second per year). Experts at Translated predict that if this trend continues, the average TTE for machine translation will reach one second around the year 2027 or 2028.
(from https://translated.com/speed-to-singularity)
Will artificial intelligence ever replace translators?
Experts at Translated emphasize an increase in the quality of the output produced: with the development of technology generating translations with fewer and fewer errors, translators will make fewer corrections, which will allow them to concentrate on issues they might have missed in a text in greater need of post-editing. “Machines will never replace humans,” reassure the authors of the report. “AI is already proving to be a valuable tool for translation professionals, helping them translate more content at a higher level”.
Linguistic disputes
In many situations, such as when it comes to law enforcement, machine translation is no substitute for a human being. When a scuffle broke out in a parking lot in front of an American supermarket, a bystander drew his gun (as he later claimed, in good faith) to prevent further escalation. He hoped to scare the individuals involved in the brawl into splitting up, but instead they called the police. Upon arrival, the officers wanted to question the self-proclaimed peacemaker, but he did not speak English very well. Nonetheless, the police officers used a free machine translation app and, based on the answers they received, decided they had enough evidence to arrest the man and bring him to justice.
David Utrilla, CEO of the Salt Lake City-based U.S. Translation Company, who was called in as an expert witness during the trial, contributed to the defendant’s acquittal. He drew the court’s attention to the pitfalls of machine translation, explaining that speech recognition technology involves a two-stage translation process: first, the input data is transcribed in the source language, and only then is it translated into the target language. If a word in the source language is not transcribed correctly, the translation will misinterpret the meaning intended by the speaker. Moreover, even an error-free transcription does not guarantee an error-free translation. Utrilla shared his experience in a post on LinkedIn – according to him, the referenced case provides excellent proof that despite revolutionary changes in the MT industry, translators will always be necessary.